In the previous blog post we talked about REST resources, Identifiers and Representations. In this post we will look at how we can connect the various resources and their representations with identifiers using the HTTP protocol .
In a RESTful system, clients and servers interact only by sending each other messages that follow a predefined protocol. The REST architectural style is primarily associated with designs that use HTTP as the transport protocol. Even though we always associate the web with HTTP, it is but one of the long lived and dominant protocols. Protocols such as FTP, Gopher, Archie, Veronica, Jughead, Prospero etc. were part of the ecosystem but gave way to HTTP as it began to emerge as the dominant protocol. Some of the goodness of these protocols were also folded into the HTTP specification.
HTTP is an open protocol that defines a standard way for user agents to interact with both resources and the servers that produce the resources. It is an application-level protocol that defines operations for transferring representations between clients and servers. HTTP is a document-based protocol, in which the client puts a document in an envelope and sends it to the server. The server responds by putting a response document in another envelope and sending it back to the client. As an application protocol, HTTP is designed to keep interactions between clients and servers visible to libraries, servers, proxies, caches, and other tools. Visibility is a key characteristic of HTTP. When a protocol is visible, caches, proxies, firewalls, etc., can monitor and even participate in the protocol. Features like Caching responses, automatically invalidating cached responses, detecting concurrent writes, and preventing resource changes, Content negotiation and Safety and Idempotency depend entirely on keeping requests and responses visible.
The Uniform Interface
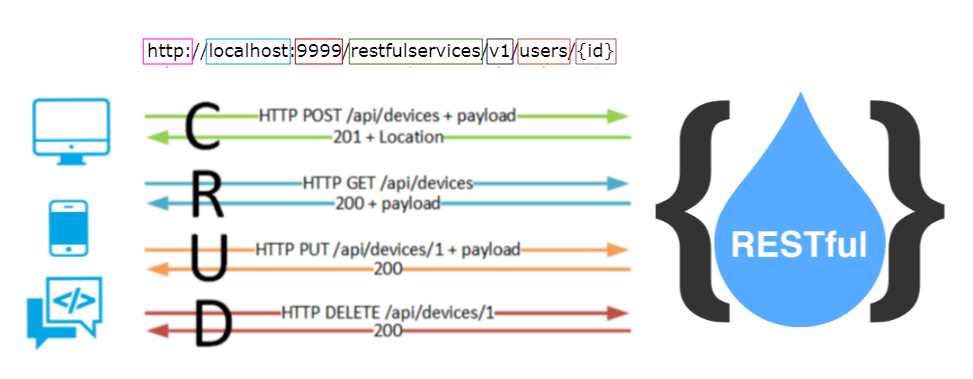
HTTP provides a uniform interface to operate on resources representations. These methods are standardized and provide expected results across all implementations. The HTTP standard defines eight distinct kinds of messages. In this standard, methods such as GET, POST, PUT, and DELETE are all operations on resources. This uniform interface makes using services similar across the web. All clients understand what a GET on a resource would result in and this knowledge is implicit in the uniform interface.
GET
The HTTP standard says that a GET request is a request for a representation. It is intended to access a resource in a read-only mode and not change any resource state on the server. GET is the most used and well-known verb. GET is a safe method. The infrastructure of the Web strongly relies on the idempotent and safe nature of GET. Clients count on being able to repeat GET requests without causing side effects. A GET for a URI returns a copy of the resource that URI represents. One of the most key features of GET requests is that the result of a GET can be cached. Caching GET requests also contributes to the scalability of the Web. Another feature of GET requests is that they are considered safe, because according to the HTTP specification, GET should not cause any side effects—that is, GET should never cause a change to a resource. A GET request is bot idempotent and safe. The most common response code to a GET request is 200 (OK). Redirect codes like 301 (Moved Permanently) are also common when the underlying resource location has moved.
POST
Normally used to send a new resource into the server (create action). POST, which indicates a request to create a new resource, is the next most used verb. A post is used to create a subordinate resource which are resources which exist in relation to a parent resource. An example of this is using a post to create a customer record where the individual customer record is a subordinate of the customer table or using post to create a single blog entry where it is a subordinate to the blog posts. A POST is used to create or append a resource identified by a service generated URI. POST is not an idempotent operation. The POST method is a way of creating a new resource without the client having to know its exact URI. The common response to a POST is a ‘201 created’ response with the location header specifying the location of the newly created subordinate resource. Another common response code is 202 (Accepted), which means that the server intends to create a new resource based on the given representation asynchronously at a later point of time. A post is neither idempotent nor a safe call. Multiple calls to post with the same representation will create multiple copies.
PUT
A PUT is used to update a resource using a URI computed by the client. PUT is an idempotent operation and expects the whole resource to be supplied rather than just the changes to the resource state. This guarantees that if you use PUT to change the state of a resource, you can resend the PUT request and the resource state won’t change again. PUT encapsulates the whole state of the representation ensuring that if there is any failure due to transient network or server error the operation can be safely repeated. PUT replaces the resource at the known URL if it already exists. If you make a PUT request and never get a response, just make another one. If your earlier request got through, your second request will have no additional effect.
DELETE
Used to delete a resource. On successful deletion, the operation returns a HTTP status 200 (OK) code. A DELETE operation is idempotent. However, a repeated call to delete a resource should result in a 404 (NOT FOUND) or better still a 410(GONE) since it was already removed and therefore is no longer available.
PATCH
Modify part of the state of this resource based on the given representation. PATCH is like PUT but allows for fine-grained changes to the resource state. PATCH is neither safe nor idempotent. PATCH is not defined in the HTTP specification. It’s an extension designed specifically for web APIs, and it’s relatively recent ( RFC 5789 ).The PATCH method returns response code 200 (OK) or 204 (No Content) if the resource modified does not exist.
HEAD
Not part of the CRUD actions, but the verb is used to ask if a given resource exists without returning any of its representations. HEAD retrieves a metadata only representation of the resource. HEAD gives you exactly what a GET request would give you, but without the entity-body. HEAD returns the full headers, so we can do a LastModified/ContentLength check to decide if we want to re-download a given resource. HEAD can be used for existence and cache checks. HEAD is safe and does not alter server state. It is also Idempotent with duplicate subsequent requests being free from any side effects.
OPTIONS
Not part of the CRUD actions but used to retrieve a list of available verbs on a given resource (i.e., What can the client do with a specific resource?). All CORS requests are preceded with an OPTIONS request also called as a preflight request. OPTIONS is both safe and Idempotent. HTTP has strict standards for what the envelopes should look like but is not concerned about what goes inside it. When I hit the web site https://pradeepl.com the below request is generated (we can see this using the chrome dev tools –F12 on the chrome browser)
HTTP Request
GET /2016/09/10/git-basics/ HTTP/1.1
Host: pradeepl.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,_/_;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.8
The first line in the above request message describes the protocol (HTTP1.1) and the method GET) used by the client. The next few lines are request headers. By inspecting these header attributes and lines , any piece of software that understands HTTP can formulate not only the intent of the request but also how to parse the body of the message.
Major parts of the HTTP request
The HTTP request primarily consists of
The HTTP method - In this request, the method is “GET.” also called the “HTTP verb” or “HTTP action.". User agents only interact with resources using the prescribed HTTP verbs.
The path - In terms of the envelope metaphor, the path is the address on the envelope. In the above request the path is /2016/09/10/git-basics/ with the hostname header completing the path.
HTTP request headers - These are metadata: key-value pairs that act like informational stamps on envelope. This request has the headers: Host, Connection, User-Agent, and Accept.
The entity-body/document/representation - This is the document that inside the envelope also called as payload.
HTTP Response
The HTTP response is also a document in an envelope. It’s almost identical in form to the HTTP request. The HTTP request above results in the below HTTP response.
HTTP/1.1 200 OK
Date: Tue, 20 Sep 2016 02:36:14 GMT
Server: Apache Phusion\_Passenger/4.0.10 mod\_bwlimited/1.4 mod\_fcgid/2.3.9
X-Powered-By: PHP/5.3.29
Vary: Accept-Encoding,Cookie
Content-Encoding: gzip
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
Major parts of the HTTP response
The major parts of the HTTP response are
The HTTP response code - This three-digit numeric code tells the client whether its request went well or poorly, and how the client should regard this envelope and its contents. In addition to verbs, HTTP also defines a collection of response codes, such as 200 OK, 201 Created, and 404 Not Found. verbs and status codes provide a general framework for operating on resources over the network. Detailed information on response codes and verbs are below.
HTTP response headers - Just as with the request headers, these are informational stickers on the envelope. This response has header data such as Date, Server, Content-encoding and so on.
The entity-body or representation - This is the document inside the envelope containing any response from the server. The entity-body is the fulfillment of the GET request and contains the representation requested.
HTTP Response Codes
A defining feature of RESTful architecture is its use of HTTP response codes. Since the response code isn’t part of the document or the metadata, the client can see whether an error occurred just by looking at the first three bytes of the response. HTTP response codes are underused on the human web but are key on the programmable web where API’s can take different paths based on the response codes. There are 39 official HTTP response codes but only about 10 are used frequently in daily use.
The status codes are divided into five categories based on the intent to be communicated. Each category has detailed status codes representing the intent in detail.
- 1xx: Informational - Communicates transfer protocol-level information
- 2xx: Success - Indicates that the client’s request was accepted successfully.
- 3xx: Redirection - Indicates that the client must take some additional action in order to complete their request.
- 4xx: Client Error - This category of error status codes indicates issues with the clients request.
- 5xx: Server Error - The server takes responsibility for these error status codes.
Some of the commonly used HTTP status codes are below: -
200 OK - The request went fine, and the content requested was returned. This is normally used on GET, PUT and PATCH requests.200 (OK) must not be used to communicate errors in the response body
201 Created - The resource was created, and the server has acknowledged it. It could be useful on responses to POST or PUT requests. Additionally, the new resource could be returned as part of the response body.
202 Accepted - This response code indicates that the clients request will be handled asynchronously. It confirms that the request was valid but does not guarantee the outcome of the request. The response indicates the status of the resource and can point to a status monitor to provide updates on the request status.
204 No content - The action was successful but there is no content returned. Useful for actions that do not require a response body, such as a DELETE action. This indicates that the client asked the server to delete a resource which was successfully deleted.
301 Moved permanently - This resource was moved to another location and the location is returned. This header is especially useful when URLs change over time (maybe due to a change on version, a migration, or some other disruptive change), keeping the old ones and returning a redirection to the new location allows old clients to update their references in their own time.
400 Bad request - The request issued has problems (might be lacking some required parameters, for example).The server cannot or will not process the request due to something that is perceived to be a client error A good addition to a 400 response might be an error message that a developer can use to fix the request.400 is the generic client-side error status, used when no other 4xx error code is appropriate.
401 Unauthorized - Especially useful for authentication when the requested resource is not accessible to the user owning the request. A 401-error response indicates that the client tried to operate on a protected resource without providing the proper authorization. It may have provided the wrong credentials or none.
403 Forbidden - The resource is not accessible, but unlike 401, authentication will not affect the response. This indicates that the server understood the request but refuses to authorize it .A 403 response is not a case of insufficient client credentials; that would be 401 (“Unauthorized”). REST APIs use 403 to enforce application-level permissions.
404 Not found - The URL provided does not identify any resource. A good addition to this response could be a set of valid URLs that the client can use to get back on track (root URL, previous URL used, etc.). If a representation or resource is permanently moved or deleted, then a 410 GONE status is a preferred way of indicating the same to the client.
405 Method not allowed. The HTTP verb used on a resource is not allowed. For instance, doing a PUT on a resource that is read-only.
500 Internal server error - A generic error code indicating that the server encountered an unexpected condition that prevented it from fulfilling the request. Normally, this response is accompanied by an error message explaining what went wrong.
The above methods, status codes and messages define the protocol semantics of HTTP. Understanding the HTTP verbs, status codes and request response messages are key to defining restful architectures successfully on the HTTP protocol. We now understand the basic plumbing involved in RESTful architectures and in the next blog post we will look at the architectural constraints of REST.
