The Web has radically transformed the way we produce and share information. It has democratized information sharing and has revolutionized how information is created and shared. It has also been through major inflection points named only as software engineers would.
Web 1.0 – Was about static pages.
Web 2.0 – Is/was about responsive, dynamic content targeted for various form factors such as mobile and tablets. It has evolved primarily into a “Mobile First” movement. Web 2.0 is also largely about User generated content and Social Media
Web 3.0 – is about being API First. It is about IOT devices, wearable’s, smart watches, Smart devices. Building applications to cater to humans and apps alike. It is about connective intelligence, connecting data, concepts, applications, and people.
With this focus on “API first”, as developers we need to worry about “How consumable is the API? Does it follow standards? is it secure? How do you handle versioning?”
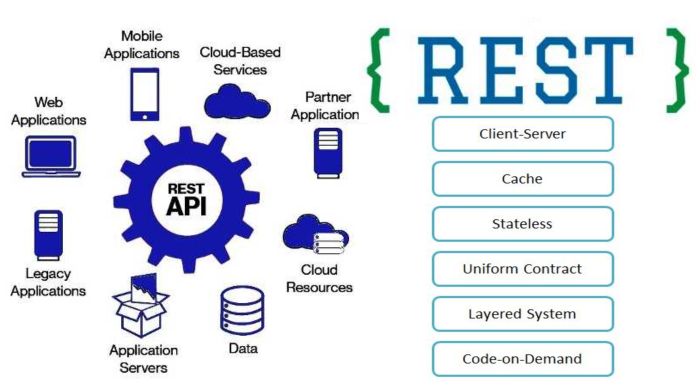
There are various architectural models for developing API First systems. such as REST, SOAP, gRPC etc. One of the foremost models gaining a lot of ground currently is REST. REST stands for Representational State Transfer. Rest is a client server communication model which is stateless, resource based, and Idempotent. As an architectural model REST defines Resources, Identifiers, and state representations as basic blocks for building API’s. REST is not a protocol, a file format, or a development framework, it is a set of design constraints. These design constraints collectively called the Fielding’s constraints were first identified in Roy T. Fielding’s 2000 dissertation on software architecture, which gathered them together under the name “REST". In the real-world REST uses HTTP as the protocol and Web servers as REST servers.
REST Fundamentals
The REST architectural model is primarily used to build API’s generally called as RESTful API’s. These are based on fundamental building blocks of REST as detailed below.
Resources
Resources are the fundamental building blocks of web-based systems. Anything that can be named can be a resource (Person, Product, device, web page etc.). Almost anything can be modelled as a resource and then made available for manipulation over the network. The only restriction is that every resource must have a globally unique address. On the Web, we use a URL to give each resource a globally unique address. Giving something a URL turns it into a resource.
Resources Identifiers
With so many different resources, they all should be accessible via some identity and should be identified uniquely. The web provides an URI (Unique resource identifier) for this purpose. The relationship between URIs and resources is many-to-one. A URI identifies only one resource, but a resource can have more than one URI pointing to it. A URI takes the form
Resource Representations
Resources can have multiple representations. A representation is a machine-readable explanation of the current state of a resource. For example one application might represent a person as a customer with an XML representation, while another might represent the same as an image of a person in jpeg and another as the persons voice sample in an mp3 format. A resource is an information representation of a real-world object/process and as such may have many representations as compared to the real world.
Access to a resource is always mediated by way of its representations. This separation between a resource and its representations promotes loose coupling between backend systems and consuming applications. It also helps with scalability since a representation can be cached and replicated. The Web doesn’t prescribe any structure or format for resource representations. Representations can just as well take the form of an image, a video, a JSON document or a text file. This ecosystem of formats (which includes HTML for structured documents, PNG and JPEG for images, MPEG for videos, and XML and JSON for data), combined with the large installed base of software capable of processing them, has been a catalyst in the Web’s success.
Since a resource can have multiple representations, the client needs to negotiate and indicate the representation needed by the it. There are two ways of doing this. The first is content negotiation, in which the client distinguishes between representations based on the value of an HTTP header. Using content negotiation, consumers can negotiate for specific representation formats from a service. They do so by populating the HTTP Accept request header with a list of media types they’re prepared to process. It is ultimately up to the owner of a resource to decide what constitutes a good representation of that resource in the context of the current interaction, and hence which format should be returned. The resource type returned is also always specified in an HTTP response as one of the HTTP headers (Content-Type). The second is to give the resource multiple URLs—one URL for every representation. When this happens, the server that publishes the resource should designate one of those URLs the official or “canonical” URL.
Putting it together- How resources, identifiers, and representations drive interactions
On the web we need to act on objects and subjects represented by resources. These resources are acted upon through verbs provided by HTTP methods. The four main verbs of the uniform interface are GET, POST, PUT, and DELETE. These verbs are used to communicate between systems. HTTP also defines a set of response codes to respond back to verbs such as 200 OK, 201 Created, 301 Moved Permanently, 303 See Other, 404 Not Found etc. Together verbs and status codes provide a general framework for operating on resources over the network. You can call GET on a service or resource as many times as you want with no side effects
Comparison with other Communication architectures
REST vs SOAP
SOAP stands for Simple Object Access Protocol. REST is centered around resources, each accessible via a URI, while SOAP actions are defined in the protocol and the body of the message. SOAP, with its extensive use of XML, requires more bandwidth and processing power. REST uses standard HTTP and is more lightweight, making it suitable for web services that are exposed on the internet. SOAP supports built-in error handling and can be used with a variety of protocols, whereas REST typically uses standard HTTP error responses.
REST vs gRPC
Both REST and gRPC are used for client-server communication. They are used for building APIs that allow different software systems to communicate with each other. REST API’s typically use JSON as the data exchange format while gRPC uses protobuf (Protocol Buffers). Protobuf is a binary format that is more efficient than JSON and less verbose. However, JSON is human readable unlike Protobuf which is binary ( think debugging ). The binary nature of protobuf combined with the fact that it utilizes multiplexing on HTTP2 makes it better from a performance perspective. gRPC natively supports Unary, Server streaming, Client streaming, and Bidirectional streaming. This means both the client and the server can send and receive multiple requests and responses simultaneously on a single connection. REST is primarily a request-response model where the client must wait for the server to respond. gRPC uses its own status codes, which are separate from HTTP status codes, whereas REST uses standard HTTP status codes. The REST architectural style works better for public facing API’s due to its ease of understanding. It works better for simpler, synchronous client-server interactions. gRPC works better for real-time or streaming API’s. It is ideal for API’s that are built for high load and with higher performance expectations.
REST in the real world
The REST architectural style is used to design and implement different architectures. REST aligns well with microservices design due to its scalable and independent nature. Each microservice can expose a RESTful API, allowing services to communicate seamlessly and be independently developed, deployed, and scaled. REST’s statelessness is key in microservices, as it simplifies the interaction between services and enhances the system’s resilience. REST APIs are pivotal in the API economy, enabling businesses to extend their services and data to external developers and partners. They foster a vibrant ecosystem by allowing easy integration with various platforms and services, thereby enhancing innovation and collaboration. REST’s simplicity and statelessness make it suitable for the constrained environments of IoT. RESTful APIs facilitate efficient communication between IoT devices and servers. The lightweight nature of REST is advantageous in edge computing scenarios where resources are limited and low latency is crucial.
In the next blog post we will look at how resources, resource representations and resource identifiers come together to drive interactions in a RESTful manner.
