Cloud Native architecture
Designing applications for the cloud introduces a unique set of challenges and opportunities. Cloud-native applications operate in a fundamentally distributed environment, demanding designs that anticipate and gracefully handle uncertainties like network partitioning, transient failures, and hardware issues. Beyond these traditional concerns, cloud environments add new complexities: quota restrictions, cost optimization, and dynamic service availability. While cloud infrastructure mitigates many of these aspects, effective design is paramount. The 12-Factor App principles offer foundational guidance for building robust cloud-native applications that thrive under these constraints.
Cloud native applications also need to be designed to take advantage of the functionality offered by hyper-scaled infrastructure. Cloud infrastructure can be scaled up, scaled out or scaled down very quickly. This allows the design to react to changes in demand quickly. Reactive architectures are well suited for cloud-based and distributed systems. Systems built using reactive architectural principles are called reactive systems.
What are Reactive Systems?
At their core, Reactive Systems are distributed systems characterized by their ability to be Responsive, Resilient, Elastic, and Message-Driven. Imagine a system that doesn’t just work, but excels even under immense pressure or in the face of unexpected failures. That’s the promise of Reactive Systems.
Reactive Systems take a fundamental shift in mindset:
- Don’t assume the world is stable — assume it will change at any moment.
- Don’t assume failures are rare — assume they will happen and plan for them.
- Design with asynchronicity as the baseline — and embrace eventual consistency as a reality.
More than technology, Reactive Systems require a design philosophy:
Design for change, for recovery, and for responsiveness under any load.
These systems are designed to be reliable, flexible, and loosely coupled, making them inherently scalable and resilient. This approach simplifies development and makes future changes easier to implement. Instead of collapsing under duress, Reactive Systems are profoundly tolerant of failure, meeting challenges with elegance rather than catastrophic outages. They adeptly handle requests, maintaining performance even when heavily loaded or encountering component failures, and communicate asynchronously to enable independent scaling of their parts.
The Reactive Manifesto: A Guiding Blueprint
To address the complexities of modern distributed systems, a collective of industry experts distilled their knowledge into The Reactive Manifesto. This pivotal document outlines the fundamental tenets for building highly reliable and scalable applications.
First published on September 16, 2014, The Reactive Manifesto is currently at version 2.0. It serves as a living document, evolving with best practices in distributed systems design, and is publicly available on GitHub here .
Tenets of Reactive Manifesto
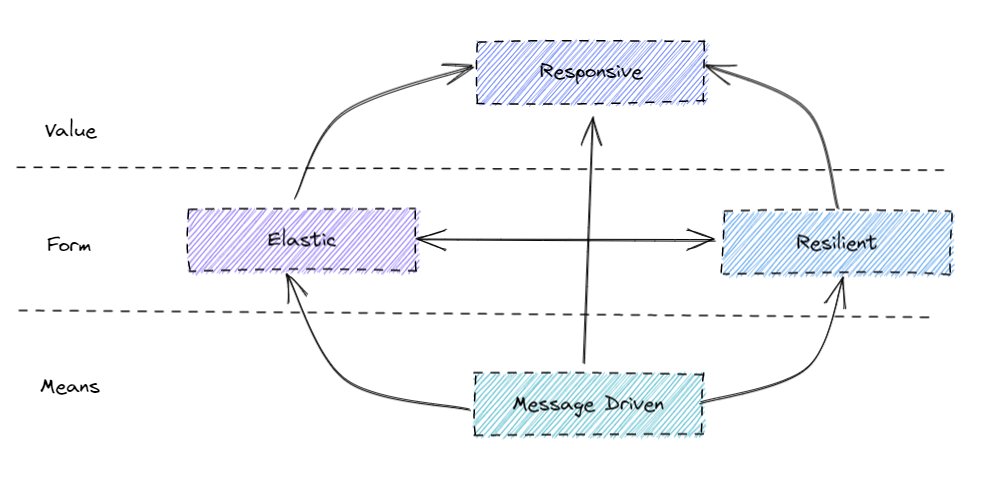
The Reactive Manifesto identifies four core design characteristics that define a Reactive System:
- Responsive: The system aims to provide rapid and consistent response times, ensuring a predictable quality of service.
- Elastic: The system remains responsive under varying workloads, scaling resources up or down, in or out, as demand dictates.
- Resilient: The system stays responsive in the face of failure, containing issues and recovering gracefully.
- Message-Driven: The system relies on asynchronous message passing to establish clear boundaries, enable isolation, and facilitate communication between components.
These tenets help build an application that is responsive, loosely coupled, elastic, message driven and highly resilient to failures.
Let us understand these tenets in further detail.
Responsive: Delivering a Timely Experience
The system responds in a timely manner if at all possible. Responsiveness is the cornerstone of usability and utility. In a reactive world, not providing a response to users when needed and not providing any response at all are one and the same. In a responsive system problems can be identified quickly and fixed effectively. Responsive systems focus on providing rapid and consistent response times, establishing reliable upper bounds so they deliver a consistent quality of service. This consistency in system responsiveness builds end user confidence and better error handling.
Resilient: Embracing Failure, Not Fearing It
A resilient system stays responsive in the face of failure. The key to resilience lies in containment and isolation: ensuring that issues within one component do not cascade and compromise the entire system. This can be achieved by isolating components from each other and ensuring that parts of the system can fail and recover without compromising the system as a whole. Resilience can be achieved by various strategies such as replication, containment, isolation and delegation.
- Replication: Running multiple instances of the same component ensures that if one fails, others can seamlessly take over, maintaining application functionality.
- Containment/Isolation: This prevents a failure in one component from affecting others. Design patterns like the Circuit Breaker pattern are classic examples of implementing effective containment, preventing repeated calls to failing services.
- Delegation: In the event of a component issue, control or responsibility can be seamlessly transferred to another similar component, often running in a distinct, isolated context.
Ultimately, resilience means a Reactive System can recover itself and continue to serve users even in the face of failures. By isolating failure handling, delegating recovery to external components, and employing replication where necessary, clients are freed from the burden of handling component failures directly.
Elastic: Scaling On Demand
Reactive systems are responsive under varying workload. Reactive Systems can react to changes in the input rate by increasing or decreasing the resources allocated to service these inputs. This implies designs that have no contention points or central bottlenecks, resulting in the ability to shard or replicate components and distribute inputs among them. Reactive Systems support predictive, as well as Reactive, scaling algorithms by providing relevant live performance measures.
The system should be able to shard or replicate components and distribute inputs among them. A system should have the ability to spawn new instances for downstream and upstream services for client service requests as and when needed. There should be an efficient service discovery process to aid elastic scaling.
Elasticity = Scale up/down + Scale out/in
1. Scale Up: When the load increases, a Reactive system should be able to easily upgrade it with more and more powerful resources (for instance, more CPU Cores) automatically, based on the demand.
2. Scale Down: Conversely, when the load decreases, resources can be automatically released (for instance, fewer CPU Cores), to optimize cost and resource utilization. .
3. Scale Out: When the load increases, a Reactive system should be able to easily extend itself by adding new nodes or servers automatically, distributing the workload horizontally.
4. Scale In: As demand subsides, excess nodes or servers can be automatically removed, shrinking the system’s footprint.
Effective Reactive Systems provide live performance measures that support both predictive (anticipating future load) and reactive (responding to current load) scaling algorithms. Efficient service discovery processes are crucial to facilitate this dynamic scaling, ensuring new instances are seamlessly integrated and accessible.
Message-Driven: The Language of Reactive Systems
Asynchronous message passing is the foundation of reactive systems. As stated in The Reactive Manifesto:
“Reactive Systems rely on asynchronous message-passing to establish a boundary between components that ensures loose coupling, isolation and location transparency. This boundary also provides the means to delegate failures as messages. Employing explicit message-passing enables load management, elasticity, and flow control by shaping and monitoring the message queues in the system and applying back-pressure when necessary. Location transparent messaging as a means of communication makes it possible for the management of failure to work with the same constructs and semantics across a cluster or within a single host. Non-blocking communication allows recipients to only consume resources while active, leading to less system overhead.”
– Reactive Manifesto
The Message-Driven approach gives us the following benefits:
- Immutability: Messages are inherently immutable, preventing unexpected side effects and simplifying concurrent processing.
- Shared-Nothing & Thread-Safe: Components communicate solely through messages, avoiding shared state and making them inherently thread-safe.
- Loose Coupling: Messages define clear contracts, decoupling components from each other’s internal implementation details.
- Location Transparency: Messages can traverse networks seamlessly, allowing components to be deployed anywhere without affecting their communication logic.
- Scalability: The asynchronous nature and loose coupling enable easy distribution and scaling of individual components.
- Resilience: By facilitating partitioning and replication, message-driven systems inherently avoid single points of failure, bolstering overall resilience.
Conclusion: Building for the Future
The reactive manifesto describes the key concepts of a reactive system and describes how each of these concepts enables building a resilient, elastic and message driven system. Reactive systems are an extensive area comprising many concepts, patterns, programming frameworks etc. The reactive manifesto provides a good grounding to help build further on these core concepts and linking them together.
