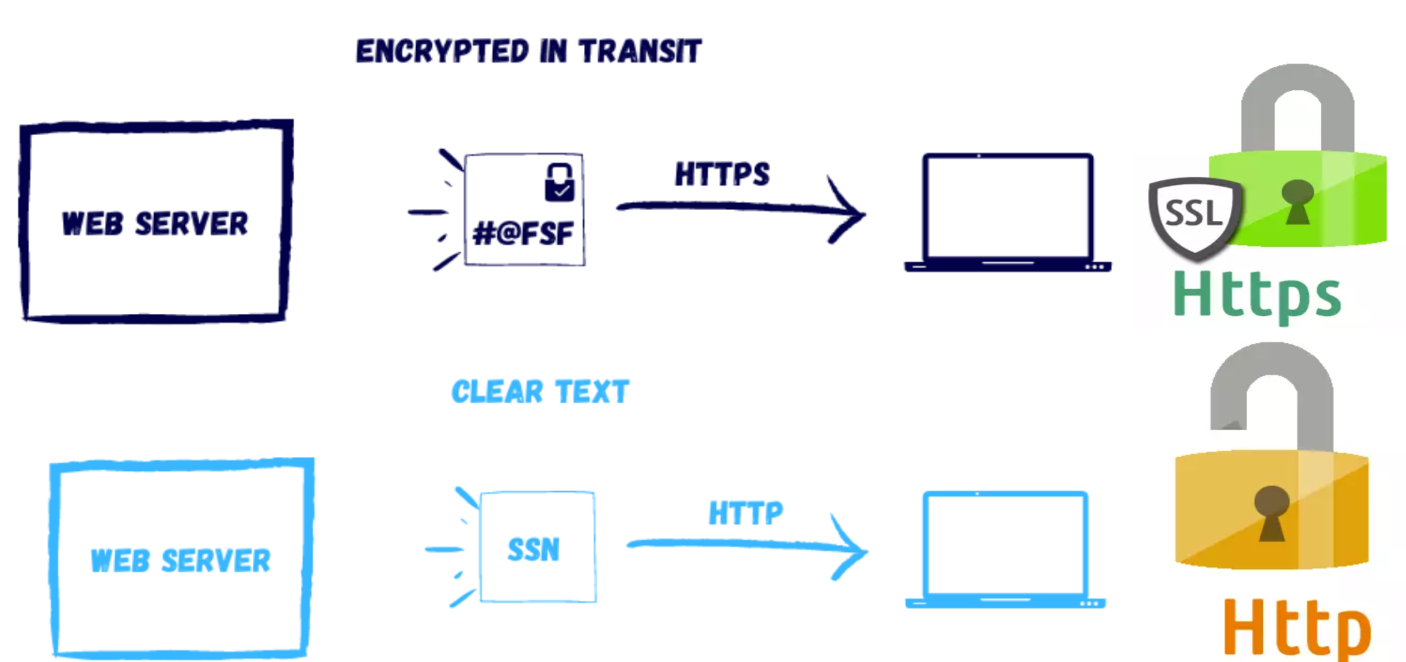
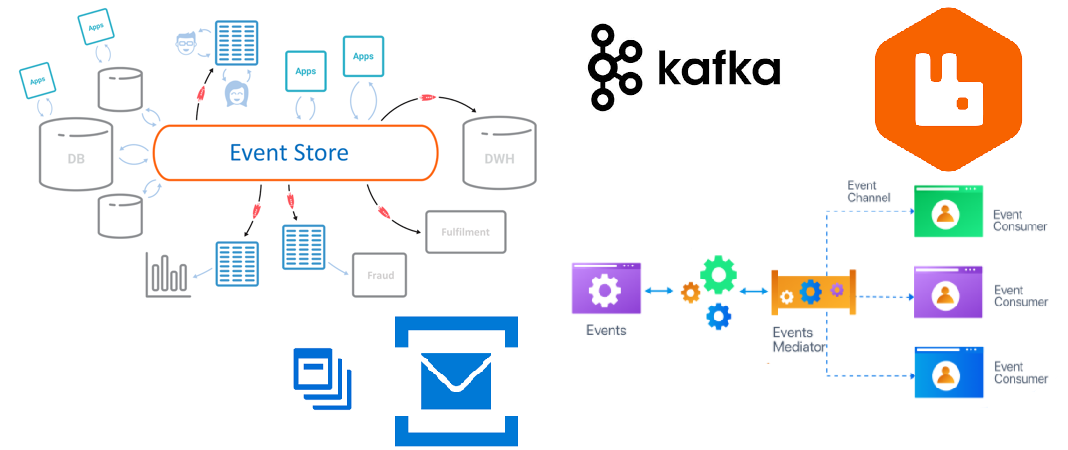
Imagine a green, sustainable city, meticulously designed for environmental harmony and efficiency. The city has many distinct localities such as neighborhoods, districts, and even villages with their own identity and cultures. This city boasts an intricate public transport system, with buses, trams, and subways efficiently transporting citizens to their destinations from its various localities. Multiple such cities are connected together in a thriving, fast-paced ecosystem. The cities are also similarly connected in an efficient and sustainable design. Each locality in a city represents a microservice, and each city in this system, a domain operating within the larger ecosystem - the application. In an ideal world, this system not only ensures smooth transit but also maintains each city’s eco-friendly ethos; balancing efficiency with sustainability. But how does this ecosystem manage to keep its vast and varied transport network running so smoothly and eco-consciously, avoiding traffic jams, pollution, and inefficiencies?
...