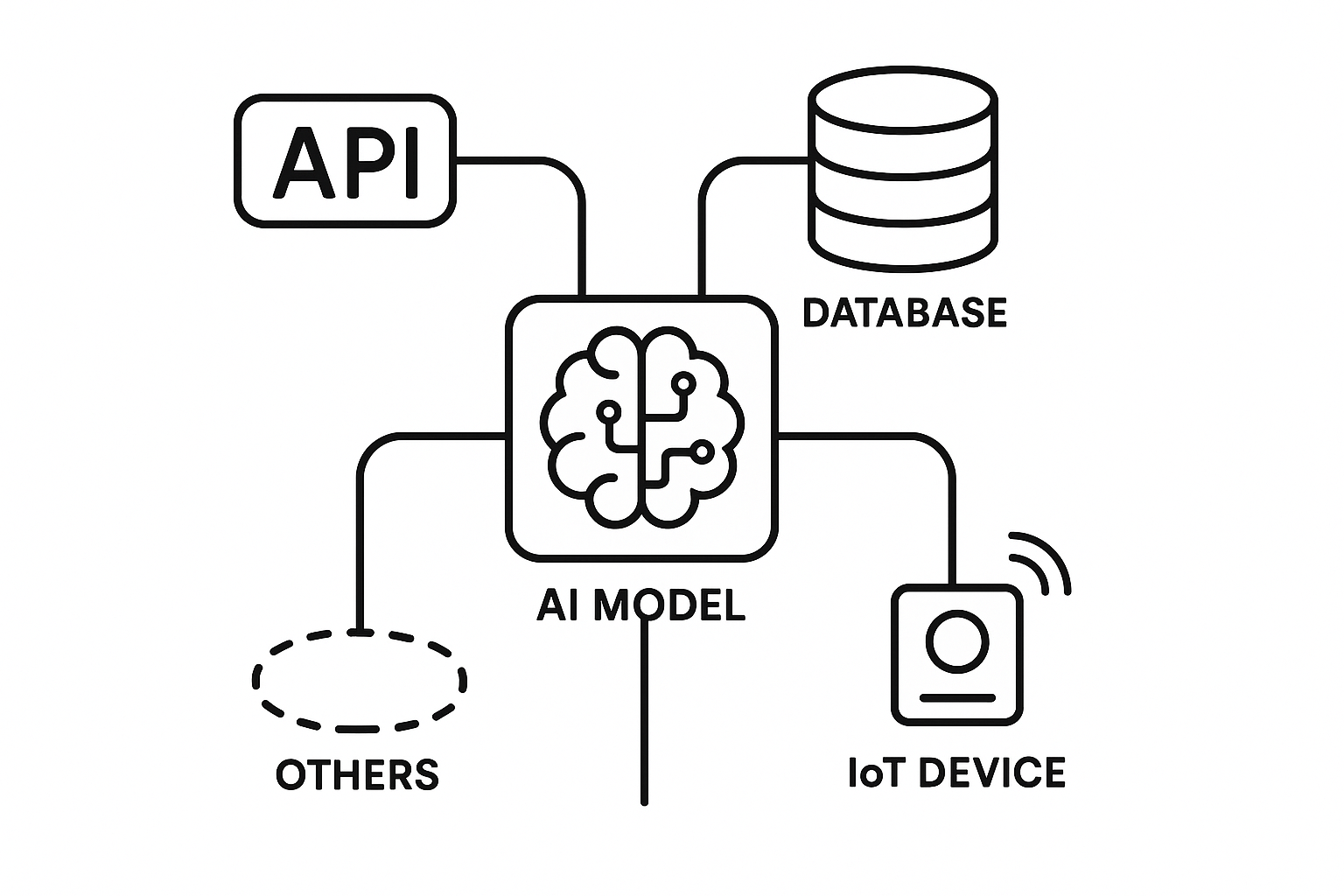
The rapid advancement of Artificial Intelligence (AI), particularly Large Language Models (LLMs), has created a pressing need for standardized methods to connect these powerful models with the external world – data sources, APIs, and specialized tools. LLMs, like those powering ChatGPT or Anthropic’s Claude, are inherently limited to the static knowledge encoded in their training data or temporarily injected via prompts. Large Language Models (LLMs) like OpenAI’s ChatGPT or Anthropic’s Claude have amazed the world with their ability to write code, summarize articles, generate reports, and answer questions. But what’s less obvious—and often misunderstood—is that these models don’t “know” anything new after their training ends.
They can’t access your company’s data, check today’s weather, query a live API, or trigger an action unless you explicitly give them that ability.
LLMs are trained on massive datasets up to a certain cutoff date (for example, September 2024 or April 2025), and beyond that, they are essentially guessing based on patterns they learned.
So while an LLM might be able to explain what an API does, it can’t call that API unless your application makes that possible. To perform meaningful real-world tasks, they need to:
- Access fresh data (e.g., live APIs, databases, or user inputs).
- Trigger external actions (e.g., send emails, update records, call APIs),
- Incorporate Contextual information (e.g., what file or project the user is working on),
- Use tools and services (e.g., code analysis platforms, orchestration engines, CLI tools).
Real-World Example: Order Lookup Chatbot in E-commerce
Imagine you’re building a customer support chatbot for an e-commerce business. A customer asks:
“Where’s my order #45677?”
An LLM can guess what kind of data might be relevant and even describe what an API might look like. But it can’t actually retrieve live order data unless you explicitly connect it to your system.
So you build a quick integration between the model and your internal order management API. The bot can now fetch order status. Great.
But then, someone wants to include tracking information—so you wire up a shipping provider like Sendle, ShipStation, or Australia Post. Then comes payment integration—maybe with Stripe or PayPal—to show refund status or receipts. Then email or SMS notifications, so the chatbot can update the customer proactively based on chat requests. Maybe even inventory checks, so the chatbot can suggest alternate products if something’s out of stock.
Suddenly, your clean one-to-one integration has become a web of brittle connectors:
- Each system has a different API,
- Some use OAuth, others use API keys,
- You have to normalize response formats,
- And you must carefully manage errors, retries, and security for each tool.
It worked when it was just one API. But as the assistant’s capabilities grow, you end up with a fragile, deeply-coupled mess of custom logic. Adding a new capability means weeks of engineering work—and testing all the old ones again.
Integrating LLMs with external systems remains complex without standardization. Every new tool or API typically requires custom plumbing. This creates fragility, slows down innovation, and leads to vendor lock-in—where applications are tightly coupled to proprietary platforms, increasing switching costs and reducing long-term flexibility. These challenges have made it difficult to deploy AI systems that are both scalable and secure.
MCP (Model Context Protocol), introduced by Anthropic, was designed specifically to solve this fragmentation. It provides a standardized, open interface for LLMs to interact with external tools and data sources—securely, modularly, and with minimal custom engineering. Think of it as a “USB-C” for AI tools: plug in a new capability, and it just works.
Why MCP?
After the previous experience of building brittle, custom integrations between AI models and external systems, developers needed something better. Each new use case—whether checking order status, scanning code for vulnerabilities, or fetching live metrics—meant repeating the same boilerplate: define a custom API contract, build tooling to adapt the model’s output, and carefully manage authentication, serialization, and errors.
This fragmentation slowed innovation and made AI assistants hard to scale, test, or secure. This fragmentation and custom-plumbing problem isn’t new. We’ve solved it before. In the 2000s, REST emerged as a standard way for web services to communicate over HTTP, saving us from a mess of proprietary XML-RPC and SOAP integrations. More recently, GraphQL , and gRPC provided a high-performance, schema-driven standard for internal microservice communication, replacing ad-hoc RPC calls. Each standard provided a common language that reduced complexity and accelerated innovation.The AI ecosystem lacked its own standard for this new type of interaction—a universal way for models to talk to tools.That’s where the Model Context Protocol (MCP) comes in.
MCP, introduced by Anthropic, is an open protocol designed to standardize these interactions. It defines how language models and agent-like systems can:
- Discover what tools and data are available,
- Invoke those tools with structured arguments,
- Receive results in a consistent, LLM-friendly format,
- And maintain context across interactions.
Because MCP is open and composable, it allows developers and tool vendors to build plug-and-play connectors that work across models and platforms. You can expose a payment API, a document store, or a CLI tool once and use it with any assistant that speaks the MCP protocol. Rather than building a new integration every time an AI model changes, you build once, plug in anywhere. By standardizing this interface, MCP shifts the developer’s focus to designing smart, secure, and useful AI workflows without reinventing the wiring for every tool or data source.
The Growing MCP Ecosystem
Since its introduction by Anthropic in late 2024 , MCP has rapidly gained traction, fostering a growing ecosystem around the standard.
Specification and Standards
MCP is positioned as an open standard, stewarded by Anthropic but open to community contribution. The core assets are publicly available:
- Specification Repository: The repo at
https://github.com/modelcontextprotocol/modelcontextprotocolhosts the specification details and the schema definitions. - Schema: The protocol contract is defined using TypeScript types first, which are then compiled to JSON Schema for cross-language compatibility.
- Documentation: The official documentation site,
modelcontextprotocol.io, provides guides, tutorials, and API references.
SDK Support
A key factor in MCP’s adoption is the availability of official Software Development Kits (SDKs) for major programming languages, facilitating the development of both clients and servers. Official or officially supported SDKs exist for almost all major languages. This broad language support significantly lowers the barrier for developers to integrate MCP into their existing technology stacks.
Industry Adoption
MCP has seen remarkably rapid adoption by major players in the AI landscape:
- Anthropic: Integrated MCP into its Claude models and Claude Desktop application.
- OpenAI: Announced support for MCP in its Agents SDK and ChatGPT desktop applications in early 2025.
- Google: Integrated MCP support into Vertex AI, the Agent Development Kit (ADK), and upcoming Gemini models, referring to it as a “rapidly emerging open standard”.
- Tool and Platform Vendors: Numerous companies, including development tool providers (Akka, Sourcegraph, Zed, Codeium, Replit), enterprise platforms (Akka, Block, Apollo), and integration platforms (Zapier, Pipedream), have adopted or built integrations for MCP.
This swift and broad uptake by leading AI companies and the wider developer community signals strong momentum. It suggests a collective recognition of the need for standardization in how AI models interact with external context and tools.
Complementary Protocols
It’s also worth noting that MCP exists within a broader landscape of emerging AI communication standards. Google, for instance, introduced the Agent-to-Agent (A2A) protocol, explicitly positioning it as complementary to MCP. While MCP focuses on standardizing how a single agent interacts with tools and data sources, A2A aims to standardize how different autonomous AI agents communicate and collaborate with each other. Understanding this distinction helps place MCP within the larger context of building complex, multi-agent AI systems.
The MCP Architecture
At its core, MCP is built around a client-server architecture that clearly separates the roles of the AI application (the Host), the intermediary that speaks the MCP protocol (the Client), and the service exposing external capabilities (the Server). This separation of concerns is fundamental to MCP’s design, promoting security, modularity, and composability.
As the diagram above illustrates, the MCP architecture is built on a clear separation of concerns. It shows how an AI-Enabled Application (the Host) interacts with External Systems by communicating through a standardized MCP Server Layer. This client-server model is fundamental to MCP’s design. Now, let’s get into the specific details of each component in that flow.
MCP Hosts, Clients, and Servers
MCP follows a client-server architecture designed to facilitate communication between AI applications and the external capabilities they need to leverage. The architecture revolves around a clear separation of roles within a client-server model. The primary components involved are:
MCP Host: The Host is the application or runtime that embeds the AI model and needs contextual capabilities. Examples include chatbots, AI-enhanced Integrated Development Environments (IDEs) like Cursor or Claude Desktop, or other custom applications integrating AI features. The host application operates or embeds the MCP Client to interact with the MCP ecosystem. The host is responsible for managing one or more MCP Clients, initiating connections, enforcing security policies, handling user interaction (including critical consent flows for tool use and data access), and potentially aggregating context from multiple servers.
MCP Client: Residing within the Host environment, the MCP Client acts as an intermediary. The Client acts as a bridge between the AI model and the external tools exposed by MCP Servers. Each Client maintains a persistent, stateful 1:1 connection with a single MCP Server and handling the specifics of the MCP protocol. It handles the specifics of the MCP protocol over the chosen transport (e.g., WebSocket), translates requests from the Host into MCP messages, manages the connection lifecycle (including initialization and capability negotiation), handles authentication with the server, and routes messages bidirectionally. Think of the MCP Client as a runtime agent or library inside the Host that speaks the MCP protocol and coordinates tool usage. The host may launch multiple clients to connect to different servers (for example, one client for a Google Drive connector, another for a database connector).
MCP Server: An MCP Server exposes one or more tools, prompts, or data resources through the standardized MCP interface. Servers operate independently and each server provides a specific set of functions or context. An MCP Server acts as a gateway, exposing external capabilities to the AI model via the standardized MCP interface. A server might provide access to specific databases, integrate with external APIs (like Stripe or GitHub), manage local file systems, or execute specific functions. They form the core of the ecosystem, acting as the bridge between the AI model’s requests (via the client) and the real-world tools or data sources. MCP Servers can be implemented as local processes communicating via standard I/O (stdio) or as remote services accessible over protocols like HTTP with Server-Sent Events (SSE). This architectural separation is fundamental to MCP’s design, promoting security and composability. The Host retains control over the user interaction and the overall context, deciding which servers to connect to and managing trust boundaries. Each server focuses on providing its specific set of capabilities, isolated from the full conversation context and other connected servers, which is crucial for managing security risks. This isolation model is critical. It ensures that a tool server can only do what it’s explicitly asked to and nothing more. The Host is always in control of which tools are available, who can use them, and when they’re called.
Now that we have a clear picture of the primary components namely the Host, Client, and Server and their roles, the next logical question is: how does a server actually expose its capabilities? What is the “language” they use to share functions, data, and instructions? This is defined by MCP’s three core primitives. Let’s dive into what they are and how they work.
Core Primitives of MCP
MCP servers expose their capabilities using three core primitives: Tools, Resources, and Prompts. These primitives define how AI models interact with the external world—by performing actions, accessing data, or shaping behavior—with structured metadata and human-in-the-loop safeguards.
Tools
Tools represent executable capabilities that the MCP server exposes to the AI model or agent allowing it to perform actions or invoke external services and APIs. Examples range from executing Kubernetes command-line interface (CLI) commands (kubectl, helm, istioctl) , calling a payment processing API, interacting with a version control system like GitHub , or any other defined action. A critical aspect of MCP Tools is how they are described. Unlike traditional APIs defined for machine consumption, MCP tool definitions are designed to be interpretable by language models.
A tool definition typically includes:
- A natural language description explaining what the tool does.
- A structured definition of inputs and outputs (e.g., using schemas).
- Any preconditions required for successful execution (e.g., a specific user must exist).
- Examples illustrating how the tool might be used in different contexts.
This metadata helps the LLM understand when and how to use a tool correctly, making the tool not just machine-callable, but AI-readable. We will be looking at tool definitions in detail in subsequent blog posts in the series.
Tools can be unsafe (they might execute code, send emails, make purchases, etc.), so MCP enforces that the user must explicitly allow a tool invocation. Typically the host will prompt the user “Allow AI to run tool X with these inputs?” and only call the server if confirmed. Tool results can be text or data; if a result is binary (e.g. an image or file generated), the server might return a reference (like a URI or an encoded blob) and the host can decide how to handle it (display to user, etc.). MCP also allows tool annotations – hints about tool behavior (like cost, side effects) – but these are considered untrusted unless from a trusted source.
Resources
Resources allow an MCP server to expose structured or unstructured data to the model. This could involve querying databases, accessing specific files or directories on a local filesystem, retrieving information from cloud storage platforms, or accessing specific data streams like customer logs. The server manages the secure retrieval and potential processing of this data based on client requests. Each resource is identified by a URI (e.g. file://, db://, http://). The server acts as a content provider. The client can request the content of a URI or list available URIs. Crucially, resources are selected by the application or user, not by the model directly. For instance, the user must choose which files or records to expose to the assistant. This ensures human oversight. The server may support searching for resources or filtering (for instance, a server could implement resources/search for keywords in documents). When a resource is fetched, the server returns its content, possibly with metadata like content type. Large resources might be chunked or streamed. Also, servers can support subscriptions.If a resource might change (e.g. a log file or an online data feed), the client can subscribe and the server will send notifications/resource_updated events with new content or diffs. Resource content is typically injected into the prompt as needed (often truncated or summarized if it’s too large, to fit the context window).
Prompts
These are reusable, server-managed templates designed to guide or enhance the AI model’s behavior and responses in specific situations. They can be used to maintain consistency in responses, simplify complex or repeated actions, or inject specific instructions or context into the model’s processing flow for certain tasks. For example, a troubleshoot-bug prompt might return a series of messages that first instruct the assistant to ask clarifying questions, then analyze logs, etc. Prompts are user-controlled: the idea is the user chooses to insert that prompt flow (like selecting a pre-made recipe). In UIs, these could surface as buttons or slash-commands for the user. They help standardize complex instructions and can be shared across apps. Importantly, because prompts come from an external source, there is a risk of prompt injection if a prompt template is malicious. Implementations should only include prompt templates from trusted servers or after user review, and even then the user should know what the prompt will do. The MCP spec advises treating tool descriptions and prompt templates as untrusted by default, unless the server is fully trusted
So far, we’ve identified all the key pieces of the puzzle:
- The architectural components (Host, Client, and Server).
- The core primitives they use to communicate (Tools, Resources, and Prompts).
Now, let’s put it all in motion. How do these components use these primitives to get a job done? This is where we look at the actual data flow and interaction patterns.
Interaction Patterns and Data Flow
Tool Access Flow
The typical tool invocation follows a request–response pattern mediated by the MCP client and server. Here’s a simplified walkthrough aligned to the diagram below:
- The Host identifies a need for an external action (e.g., user asks to check order status).
- The Host consults its registered capabilities and finds the
check_order_statustool via a connected MCP Client. - The Host instructs that MCP Client to execute
check_order_statuswith parameters (e.g., order ID), often after user consent. - The MCP Client translates the call into an MCP
tools/callrequest and sends it to its one connected Server. - The MCP Server validates inputs and executes the tool logic (e.g., calls an external API or queries a database).
- The Server returns a normalized MCP response (result or error) to the Client.
- The MCP Client delivers the result to the Host.
- The Host composes the final answer for the user (and may persist context/memory).
Resource Access Flow
While the core request–response path is the same for tools and resources, resource access has a few notable nuances:
- Discovery: Use
resources/listto retrieve descriptors; the user/host selects which URIs to expose. - Data shape: Reads return
contents[](e.g.,{ text, uri, mimeType }), not tool-defined payloads. - Consent model: Models cannot arbitrarily read files or databases; the host preselects allowed roots/URIs.
- Size and streaming: Large items are summarized, chunked, or streamed; subscriptions deliver updates.
- Prompt safety: Treat content as untrusted; summarize/redact to reduce prompt‑injection risk.
In addition to this synchronous flow, MCP supports asynchronous Notifications. Servers can proactively send these messages to clients without a preceding request, typically to inform them about relevant state changes, such as the availability of a new tool or updates to a resource the client might be interested in. This allows for more dynamic interactions and keeps clients informed about the capabilities available through the server. Overall, MCP provides a structured protocol enabling AI agents to effectively plan sequences of actions, execute those steps by interacting with real systems via tools and resources, and adapt based on the information received. This completes our high-level overview of the Model Context Protocol. We’ve established why it’s needed, what it does, and how its core primitives (tools, resources, and prompts) provide a powerful and extensible framework for AI agent interactions.
What’s Next?
Now that we’ve covered the why and what of the Model Context Protocol and its core primitives, we’re ready to put theory into practice. In Part 2 of this series , we’ll go under the hood to examine how MCP works at a protocol level. We will be looking at how
- How messages are structured using JSON-RPC 2.0
- How stateful sessions are maintained across multiple interactions
- How transports like
stdioandHTTP + SSEenable flexible deployment - What design choices make MCP secure, composable, and scalable
Stay tuned for more deep dives into MCP, including hands-on examples of building MCP Servers and Clients, exploring real-world use cases, and best practices for integrating MCP into your AI applications. The journey to mastering AI integration with MCP is just beginning!
