The artificial intelligence landscape has undergone a remarkable transformation over the past few years, and our exploration of this field has mirrored that evolution. We started with first principles , designed and implemented data architectures, built models, inferred them, and then wired those models into real systems. This post is the natural next step moving onto Agentic AI, where models mature into goal-seeking workers that can plan, use tools, act, and learn inside your environment.
We began by laying data foundations for real-world AI by understanding Lambda and Kappa architectures for batch/stream processing, and then focussing on Data Mesh as a means of scaling data ownership and discovery. As our understanding deepened, we looked under the hood at some of the infrastructure that powers modern AI. We investigated specialized databases optimized for AI workloads with Greenplum and learned how to harness GPU acceleration for TensorFlow on WSL2 , understanding that the hardware and data architecture beneath our models are just as crucial as the algorithms themselves. From those early concepts, we firmed up the conceptual base in the blog post on Demystifying AI , defining AI and Data Science and surveying core subfields. We then examined how AI models process information and generate responses through Model Inference , discovering the critical bridge between trained models and real-world applications. This wasn’t just theoretical, We built something tangible, a fraud-detection model demonstrating how machine learning algorithms can solve tangible business problems through careful data preparation, model training, and deployment.
Most recently, we’ve witnessed the emergence of a new protocol for AI integration. Through our exploration of the Model Context Protocol (MCP) we discovered how modern AI systems are breaking free from isolation, connecting to real-world tools, APIs, and data sources. We even built our own MCP server , experiencing firsthand how AI can interact with external systems in standardized, secure ways.
This progression, from understanding AI’s core concepts, to implementing practical models, to exploring the infrastructure that supports them, to finally connecting AI systems with the broader digital ecosystem has brought us to an inflection point. We’re now ready to explore Agentic AI: the next evolutionary leap where AI systems don’t just respond to queries or process data, but actively plan, reason, and execute complex multi-step tasks with minimal human intervention.
This post marks the beginning of a new chapter in our AI exploration series, where we’ll discover how the foundational knowledge we’ve built together naturally evolves into systems capable of independent action and decision-making. Welcome to the era of Agentic AI—where artificial intelligence finally becomes truly autonomous.
What Makes AI “Agentic”?
The AI revolution, for many, is a story of ever-smarter assistants. First came the chatbots, then the generative models, and most recently, the “copilots”—powerful, single-turn tools that augment human creativity and productivity. But a fundamental shift is underway. We are moving beyond passive, human-prompted models to autonomous, goal-oriented systems - what we call AI agents.
The AI systems we’ve built so far in our journey, from the fraud detection models we built to the inference servers that deploy them, represent what we might call “reactive intelligence.” These systems excel at responding to inputs: give them a transaction, and they’ll classify it as fraudulent or legitimate; provide them with an image, and they’ll identify what’s in it; feed them text, and they’ll generate a response. But they fundamentally wait for us to provide the input, define the task, and interpret the results.
Agentic AI represents a fundamental shift from this reactive design to proactive, goal-directed systems that can initiate actions, plan sequences of activities, and adapt their approach based on changing circumstances. Where traditional AI systems are like sophisticated calculators waiting for problems to solve, agentic AI systems are more like semi-autonomous colleagues capable of understanding objectives and figuring out how to achieve them. A copilot, no matter how powerful, is a reactive tool; it waits for a human prompt and provides a single, final output. An agent, on the other hand, is proactive. It has a goal, formulates a plan, takes action, and iterates until the goal is achieved.
The LLM as the Brain: A Conceptual Leap
At the heart of this shift is using a Large Language Model (LLM) not just as a text generator, but as the reasoning engine or “brain” of a more complex system. Instead of simply asking an LLM to “write a poem,” we task it with a goal like “research and summarize the latest advancements in quantum computing.”
The difference is subtle but profound. In the first case, the LLM provides a single-turn completion. In the second, the LLM must:
- Deconstruct the goal into smaller, manageable sub-tasks (e.g., “find recent papers,” “extract key findings,” “synthesize into a summary”).
- Act on each sub-task, often by using external tools (like a search engine or an API).
- Evaluate the results of its actions.
- Iterate on the process, correcting course as needed, until the final summary is produced.
This multi-step reasoning is the core difference between a passive copilot and an active agent. While a simple prompt might ask an LLM to “generate an outline for a blog post,” an agent is given the goal “write a blog post about LLM agents.” The latter requires a continuous loop of planning, execution, and reflection.
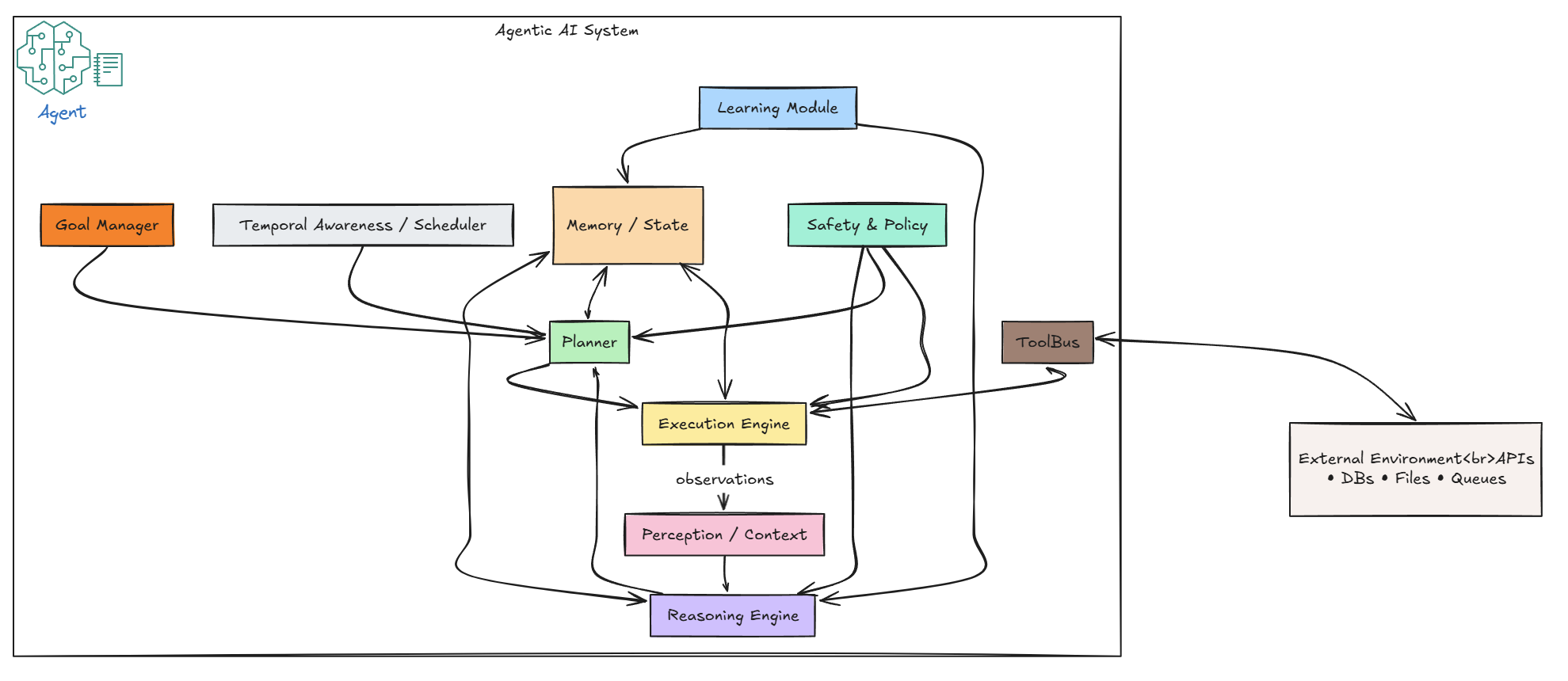
The Agentic Loop: Observe, Think, Act

The behavior of an AI agent can be modeled by a continuous feedback loop. While different frameworks use varying terminology, the core cycle remains the same:
- Perception (Observe): The agent takes in new information from its environment. This can be a user’s prompt, the output of a tool, a file’s content, or a sensor reading. In our simple case, it’s the output of the LLM itself after it has “thought” about the problem.
- Planning (Think): The agent processes the perceived information, formulates a plan, and decides on the next course of action. This is the LLM-as-a-brain part, where it reasons about the problem, the available tools, and the current state.
- Action (Act): The agent executes the planned action. This could be a tool call (e.g., using a search API), writing to a file, or generating a final response to the user.
- Memory: A crucial but often overlooked component. Memory stores the history of the agent’s actions, observations, and thoughts. This allows the agent to maintain context, learn from past mistakes, and avoid repeating work.
Core Characteristics of Agentic AI
Agentic AI systems are distinguished by several key characteristics that set them apart
1. Autonomy and Proactivity : Unlike reactive systems that simply wait for and respond to inputs, agentic AI takes the initiative. These systems are designed to identify opportunities and take iniative. They are designed to act without explicit, step-by-step instructions from a human. They demonstrate a clear goal-directed behavior, striving to achieve defined objectives with minimal human oversight, effectively taking the reins in complex scenarios. Think about the fraud detection model we built. We had to feed it specific transaction data to get a score back. An agentic fraud detection system, on the other hand, would be given a broader goal like: “Proactively monitor our systems and reduce fraudulent transactions by 5% this quarter.” It would then act on its own: monitoring data streams, identifying new suspicious patterns, and even suggesting or implementing new security rules without being asked. It owns the objective.
2. Multi-step Reasoning and Planning : An agent is a strategist. It can break down a complex objective into a sequence of smaller, manageable steps. It then executes this multi-step plan to achieve objectives. It can also adapt & change plans when circumstances change. If you gave an agent the goal, “Prepare a market analysis report on our top competitor,” it wouldn’t just search for one document. It would create a plan:
- Step 1: Search the web for their latest financial reports and news articles.
- Step 2: Access our internal sales database to compare customer overlap.
- Step 3: Analyze social media sentiment using a sentiment analysis tool.
- Step 4: Synthesize all this information into a structured report.
This ability to decompose a problem and create a multi-step plan is what separates it from simple, single-shot generative models.
3. Tool Use and Integration : Agents aren’t limited to their own knowledge; they can interact with the outside world using tools. This is precisely why our exploration of the Model Context Protocol (MCP) is so relevant. An agent’s “toolbox” can include:
- Calling APIs (like a weather API or a stock market database).
- Searching the internet.
- Accessing a private database.
- Sending emails or Slack messages.
- Writing and executing its own code.
Agentic AI takes this concept further by not just using tools individually, but by intelligently combining them. It understands which tools are available (building on MCP’s capability discovery), can select the right tool for each subtask, and can chain tools together in sophisticated ways.
4. Context Awareness : Unlike the stateless nature of many inference systems we’ve discussed, agentic AI maintains awareness of context across interactions. It remembers previous decisions, learns from outcomes, and adapts its strategies accordingly. This allows it to handle complex, multi-step tasks that require understanding of both the current situation and past actions.
5. Continuous Learning and Adaptation :Unlike traditional stateless inference systems, agentic AI is designed to maintain contextual awareness across interactions. It doesn’t just respond, it evolves. By remembering past decisions, analyzing outcomes, and integrating feedback, agentic AI continuously refines its behavior and decision-making strategies.
- Learns from experiences and outcomes : Tracks decisions and their consequences to build a richer understanding over time
- Improves performance over time : Uses accumulated knowledge to enhance accuracy, efficiency, and effectiveness.
- Adapts strategies based on feedback and results : Modifies its approach based on feedback, changing goals, or evolving environments.
Core Implementation Walkthrough
Let’s ground these ideas in code by building two implementations side-by-side. We’ll start with a traditional reactive copilot, then evolve it into an autonomous agent. This comparison will make the architectural differences concrete and highlight the fundamental shift in how these systems operate.
The table below summarizes the key differences we’ll explore:
| Aspect | Reactive Copilot | Autonomous Agent |
|---|---|---|
| Control Flow | Request → Response | Goal → Loop until complete |
| Interaction | Waits for each prompt | Self-directed iterations |
| State | Stateless (no memory) | Stateful (maintains context) |
| Execution | Single-turn processing | Multi-step reasoning |
| Autonomy | Passive, user-driven | Proactive, goal-driven |
Pattern 1: The Reactive Copilot
First, let’s see what a “copilot” call looks like: a passive response model using Akka SDK. The code for this sample is available on github here.
package com.pradeepl.agentic.copilot;
import akka.javasdk.agent.Agent;
import akka.javasdk.annotations.Component;
@Component(id="simple-copilot")
public class SimpleCopilot extends Agent {
public Effect<String> ask(String prompt) {
return effects()
.systemMessage("You are a helpful AI assistant.")
.userMessage(prompt)
.thenReply();
}
}
This copilot is exposed via an HTTP endpoint:
package com.pradeepl.agentic.copilot;
import akka.javasdk.annotations.Acl;
import akka.javasdk.annotations.http.HttpEndpoint;
import akka.javasdk.annotations.http.Post;
import akka.javasdk.client.ComponentClient;
@Acl(allow = @Acl.Matcher(principal = Acl.Principal.INTERNET))
@HttpEndpoint("/copilot")
public class CopilotEndpoint {
public record AskRequest(String prompt) {}
private final ComponentClient client;
public CopilotEndpoint(ComponentClient client) {
this.client = client;
}
@Post("/ask")
public String ask(AskRequest req) {
return client.forAgent()
.inSession("default-session")
.method(SimpleCopilot::ask)
.invoke(req.prompt());
}
}
This copilot implementation demonstrates the reactive pattern:
- Stateless: Each request is independent with no memory of previous interactions
- Single-turn: One prompt in, one response out—no planning or iteration
- Passive: Waits for explicit user input; cannot initiate actions
- No Context: Cannot build on previous conversations or learn from outcomes
While Akka SDK provides the infrastructure for scalability and resilience, this copilot pattern doesn’t leverage the actor model’s state management capabilities. It’s a simple request-response service—powerful for specific tasks, but fundamentally limited in autonomy. The SimpleCopilot.ask() method sends the user prompt to the LLM with a system message, receives a single response, and returns it. Each call is stateless: past prompts are not recalled, nor do they influence the next turn. This structure cannot learn, plan, or autonomously continue—a purely reactive system.
Model Provider Configuration
One powerful feature of Akka SDK is its ability to work with multiple foundational models through simple configuration changes. The copilot doesn’t hardcode a specific LLM provider—instead, it uses the application.conf file to determine which model to use:
akka.javasdk {
service-name = "agentic-copilot"
agent {
model-provider = openai
openai {
model-name = "gpt-4o-mini"
api-key = ${?OPENAI_API_KEY}
}
}
}
This configuration approach provides several advantages:
- Provider Flexibility: Switch between OpenAI, Anthropic Claude, Google Gemini, Azure OpenAI, or even local models (Ollama, LocalAI) without changing code
- Model Selection: Choose specific models within a provider (e.g.,
gpt-4o,claude-3-5-sonnet,gemini-2.0-flash) - Environment-based Configuration: Use environment variables for API keys and different settings per environment (dev, staging, production)
- Fine-tuning Parameters: Configure temperature, top-p, max tokens, and other model-specific parameters
For example, switching to Anthropic’s Claude is as simple as changing the configuration:
akka.javasdk {
agent {
model-provider = anthropic
anthropic {
model-name = "claude-3-5-sonnet-20241022"
api-key = ${?ANTHROPIC_API_KEY}
temperature = 0.7
max-tokens = 2048
}
}
}
Or to use Google’s Gemini:
akka.javasdk {
agent {
model-provider = googleai-gemini
googleai-gemini {
model-name = "gemini-2.0-flash"
api-key = ${?GOOGLE_AI_GEMINI_API_KEY}
}
}
}
This configuration-driven approach means your copilot code remains clean and focused on business logic, while infrastructure concerns like model selection, API authentication, and performance tuning are managed declaratively through configuration.
Pattern 2: The Autonomous Agent
Now that we’ve seen how a reactive copilot works—waiting for prompts and returning single responses—let’s transform this into an autonomous agent. The key difference isn’t just adding more features; it’s fundamentally changing the control flow from reactive to proactive.
While the copilot waits passively for each request, an agent receives a goal once and then uses the LLM to autonomously plan and execute toward achieving it. The crucial insight: the LLM itself becomes the reasoning engine that plans the multi-step execution.
Let’s build a minimal autonomous agent using the same Akka SDK Agent abstraction. The code for this sample is available on github here.
package com.pradeepl.agentic.agent;
import akka.javasdk.agent.Agent;
import akka.javasdk.annotations.Component;
/**
* Minimal Autonomous Agent using Akka SDK Agent abstraction.
*
* Key Difference: The LLM acts as the "brain" to create a complete
* autonomous execution plan using the Observe-Think-Act pattern.
*/
@Component(id = "minimal-agent")
public class MinimalAgent extends Agent {
/**
* Initialize the agent with a goal.
* The LLM is instructed to act as an autonomous agent planner.
*/
public Effect<String> executeGoal(String goal) {
// Build system message that instructs the LLM to plan autonomously
String systemPrompt = """
You are an autonomous AI agent planner. You will receive a GOAL and must
create a detailed 5-step plan to achieve it using the Observe-Think-Act pattern.
For each of the 5 steps, provide:
1. OBSERVE: What you observe/know at this step
2. THINK: Your reasoning and which tool to use (search, knowledge_base,
verify, synthesize, or finalize)
3. ACT: The specific action to take
Format your response as:
Step 1:
OBSERVE: [observation]
THINK: [reasoning and tool selection]
ACT: [specific action]
Step 2:
OBSERVE: [observation]
THINK: [reasoning and tool selection]
ACT: [specific action]
... (continue for all 5 steps)
Be specific and make each step build on the previous ones.
""";
String userPrompt = "GOAL: " + goal +
"\n\nCreate a detailed 5-step autonomous execution plan to achieve this goal.";
// Call LLM to generate the complete autonomous execution plan
return effects()
.systemMessage(systemPrompt)
.userMessage(userPrompt)
.thenReply();
}
}
This autonomous agent uses the same Akka SDK Agent abstraction as the copilot, but with a fundamentally different approach: the LLM itself becomes the autonomous planner.
How It Works
The autonomous agent implementation demonstrates a fundamental architectural shift: using the LLM itself as the autonomous planner. Rather than implementing an iterative loop in code, we leverage the LLM’s reasoning capabilities to generate a complete multi-step execution plan in a single call.
1. Single-Call Autonomous Planning
When you call executeGoal("Research the latest advancements in quantum computing"), the agent doesn’t enter an iterative loop. Instead, it:
- Constructs a specialized system prompt that instructs the LLM to act as an “autonomous AI agent planner”
- Embeds the Observe-Think-Act pattern directly in the prompt structure
- Requests a complete 5-step execution plan in a single LLM call
- Returns the fully formed plan as the response
This is fundamentally different from traditional prompt-response patterns. The LLM isn’t just answering a question—it’s generating a strategic execution plan that demonstrates autonomous reasoning.
2. The System Prompt: Programming Agent Behavior
The key to autonomous behavior lies in the system prompt design. The prompt explicitly instructs the LLM to:
You are an autonomous AI agent planner. You will receive a GOAL and must create
a detailed 5-step plan to achieve it using the Observe-Think-Act pattern.
For each of the 5 steps, provide:
1. OBSERVE: What you observe/know at this step
2. THINK: Your reasoning and which tool to use (search, knowledge_base, verify, synthesize, finalize)
3. ACT: The specific action to take
This prompt structure does several critical things:
- Sets the Agent Identity: Establishes the LLM’s role as an autonomous planner, not just a question-answerer
- Defines the Execution Pattern: Embeds the Observe-Think-Act loop as a structured output format
- Specifies Tool Awareness: Lists available conceptual tools (search, knowledge_base, etc.) that the agent should consider
- Enforces Structure: Requires formatted output that represents a complete execution strategy
3. AgentState: Foundation for Future Statefulness
The implementation includes an AgentState class with fields for goal, memory, current step, and completion status:
public static class AgentState {
public String goal;
public List<String> memory;
public int currentStep;
public int maxSteps;
public boolean completed;
}
While this state structure isn’t actively used in the current single-call implementation, it establishes the foundation for evolving toward true stateful agents. This design anticipates future enhancements where:
- Memory would accumulate observations and results across actual execution steps
- Step tracking would monitor progress through the plan
- Completion flags would signal when goals are achieved
4. Why This Pattern Demonstrates Agency
Despite its simplicity, this implementation captures the essence of agentic behavior:
- Goal-Directed: The entire system is oriented around achieving a specific objective
- Autonomous Planning: The LLM independently determines what steps are needed, in what order
- Multi-Step Reasoning: The plan demonstrates forward-thinking across multiple stages
- Tool Awareness: The agent considers which tools to use at each step (even if conceptually)
- Structured Thinking: The Observe-Think-Act pattern ensures systematic reasoning
The “agentic” quality emerges not from complex iteration machinery, but from how we’ve instructed the LLM to think. By framing the prompt as an autonomous planning task rather than a simple question, we’ve shifted the LLM’s output from reactive answers to proactive strategies.
5. From Conceptual to Real Tools: Integrating with Model Context Protocol
While our current implementation mentions tools conceptually in the prompt (search, knowledge_base, verify, synthesize, finalize), the real power of agentic AI emerges when these become actual, executable tools. This is where the Model Context Protocol (MCP)
becomes essential.
Through MCP, agents can evolve from planning systems into action-taking systems by connecting to real-world capabilities:
- Research Local Knowledge Bases: Query vector databases, document stores, or enterprise knowledge repositories to gather information specific to your domain
- Query Databases: Execute SQL queries, access NoSQL databases, or retrieve data from data warehouses to inform decision-making with real-time information
- Perform Actions: Trigger workflows, send notifications, update records, or orchestrate complex business processes across multiple systems
- Access External APIs: Integrate with third-party services, weather APIs, stock market data, or any HTTP-accessible service
By building MCP servers with Akka
, you can expose these capabilities as standardized tools that your agent can discover and use dynamically. The agent’s planning capabilities—demonstrated in our MinimalAgent implementation—combined with MCP’s tool execution framework creates a complete autonomous system capable of both reasoning and action.
This integration transforms the conceptual tools in our prompt from placeholders into functional capabilities, bridging the gap between autonomous planning and real-world execution.
Core Takeaways from the Implementation
Our minimal agent is a powerful illustration, but it’s important to understand its limitations.
- Naive Memory: The “memory” is naïvely concatenated messages—it doesn’t scale to large contexts, nor can it manage long-term knowledge efficiently. As mentioned, appending to a list is not a scalable memory solution. Production-grade agents use techniques like sliding window memory, summarization, or offload context to vector databases for long-term recall.
- No External Grounding: The agent cannot interact with the outside world. Without external grounding (like APIs or sensors), the agent is still at the mercy of the LLM’s statistical patterns; errors can propagate unchecked. True agency requires the ability to act upon and perceive a real environment.
- Error Handling: What if a tool fails? Or the LLM returns a malformed response? A robust agent needs sophisticated error handling, retry mechanisms, and the ability to self-correct its plan when things go wrong.
Conclusion
We’ve taken the first crucial step in our journey, moving from passive, single-turn copilots to proactive, autonomous agents. The paradigm shift is not in the LLM itself, but in the architecture we build around it. By wrapping the LLM in an agentic loop of Perception, Planning, Action, and Memory, we unlock a new class of applications capable of tackling complex, multi-step goals. Our simple akka sdk based java implementation, while basic, reveals the core principles: the power of the system prompt to define an agent’s purpose, the necessity of memory for stateful reasoning, and the loop as the engine of autonomy. This foundation sets the stage for the rest of our series, where we will explore adding tools, building robust memory systems, and designing multi-agent architectures.
What’s Next?
Now that we understand what makes AI agents unique - their ability to plan, act, and learn independently - the next big question is: how do we build them in a way that’s reliable and scalable? That’s where the Akka Actor Model comes in. It offers a fresh approach to handling concurrency and state, which is key for building resilient agents that can work together without stepping on each other’s toes.
In Part 2: The Akka Actor Model - A Foundation for Concurrent AI Agents
, we’ll explore why actors – not traditional threads or shared memory – are a perfect fit for agentic AI. We’ll evolve our MinimalAgent into a production-ready SimpleAgent that handles thousands of concurrent sessions, maintains persistent memory, and integrates real tools. Plus, I’ll walk you through a complete Akka SDK implementation with deployment and operationalization strategies.
Ready to see how the foundation of concurrent agents is built? Continue to Part 2 → As we come to a close, let me leave you with something to consider:
If an agent’s autonomy is defined by its ability to execute a plan, what is the minimum number of steps required for a system to be considered truly “agentic”?
